One minute
A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
Abstract
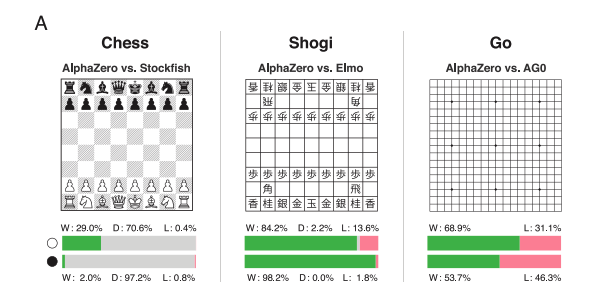
The game of chess is the longest-studied domain in the history of artificial intelligence. The strongest programs are based on a combination of sophisticated search techniques, domain-specific adaptations, and handcrafted evaluation functions that have been refined by human experts over several decades. By contrast, the AlphaGo Zero program recently achieved superhuman performance in the game of Go by reinforcement learning from self-play. In this paper, we generalize this approach into a single AlphaZero algorithm that can achieve superhuman performance in many challenging games. Starting from random play and given no domain knowledge except the game rules, AlphaZero convincingly defeated a world-champion program in the games of chess and shogi (Japanese chess), as well as Go.
117 Words
2018-12-07 00:00 +0000